Big Data se refiere al tratamiento, análisis y explotación de grandes volúmenes de información, en velocidad de respuesta y con una variedad de data que con la tecnología actual sería difícil tratar. El contexto actual se presenta como una oportunidad para aprovechar Big Data en la creación de ventajas competitivas. Dentro de BI y del Mercado local se está alcanzando una madurez con respecto al uso de analítica para la toma de decisiones. Sin embargo, aún se tiene un desfase con respecto a economías más desarrolladas.
Big Data se presenta como una oportunidad de crear valor y posicionar a las áreas de analytica como las áreas más importantes dentro de una organización.
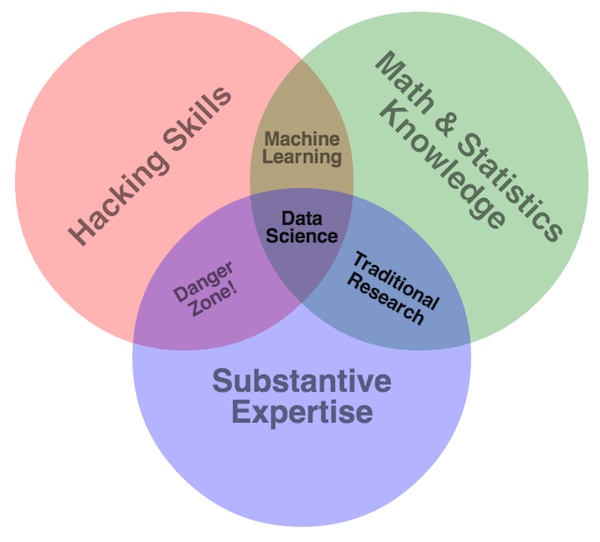
En principio debemos entender que el principal producto de Analytica Predictiva es el conocimiento del negocio. El que se encuentra en los datos de manera implícita. Es decir, no se puede extraer este tipo de conocimiento con técnicas tradicionales de análisis. Muchas áreas de BI generan conocimiento; sin embargo, el área de analytica predictiva se realiza mediante técnicas avanzada de análisis de datos. Algunas de ellas ligadas a modelos estadísticos avanzados y las otras a Machine Learning.
Otro aspecto importante es que el conocimiento que se genera con analytica predictiva debe ser accionable para generar valor dentro de la compañía. Por tanto, un área de analytics y modelos predictivos debería fundamentarse en 4 grandes aspectos: Impacto en el negocio, Disrupción, Liderazgo y Trabajo en Equipo.
Alto impacto en el negocio.
El objetivo de la dirección de BI es aportar conocimiento al negocio. Es por eso que se debe de asegurar la entrega oportuna de información tanto en la velocidad que exige el mercado como en la oportunidad de generar el más alto valor. Velocidad. Es importante asegurar el delivery de los modelos y análisis avanzados en el momento oportuno y con la calidad de información adecuada. Optimizar la operativa interna de producción de modelos en esta parte se vuelve clave para alinear los tiempos de respuesta al ritmo que el mercado lo exige. Poner foco en producción de modelos de alto impacto y poco uso de recursos. Limitar producción de modelos de bajo impacto y alto consumo en recursos.
Valor al Negocio. Es clave identificar la necesidad específica del negocio. Para ello se debe de conocer el ciclo de vida del producto, el público objetivo y el mix de marketing. Conociendo estos aspectos se hace más fácil reconocer la oportunidad de negocio, diseñando un nuevo: público objetivo, Canal, Precio y/o Producto…













 métodos supervisados por ejemplo le sirven a Facebook para identificar el rostro de nuestros amigos cada vez que publicamos una foto en el muro. Otra aplicación sencilla es Shazam que puede identificar la canción que estamos escuchando con solo acercar el teléfono móvil.
métodos supervisados por ejemplo le sirven a Facebook para identificar el rostro de nuestros amigos cada vez que publicamos una foto en el muro. Otra aplicación sencilla es Shazam que puede identificar la canción que estamos escuchando con solo acercar el teléfono móvil.
 Big Data como término, si es nuevo; sin embargo, las herramientas de computación distribuida, técnicas de análisis y visualización de datos no son necesariamente nuevas.
Big Data como término, si es nuevo; sin embargo, las herramientas de computación distribuida, técnicas de análisis y visualización de datos no son necesariamente nuevas. formación de Redes Sociales como Facebook o Twitter al conjunto de datos que se tiene internamente en cada organización. Lo cierto es que la analítica de redes sociales funciona muy bien en su propio ecosistema, es decir analizar por ejemplo los comentarios de Twitter son bastante interesantes cuando se refieren a una marca; pero el reto que no se ha cumplido es enlazar este mundo con los clientes de cada organización.
formación de Redes Sociales como Facebook o Twitter al conjunto de datos que se tiene internamente en cada organización. Lo cierto es que la analítica de redes sociales funciona muy bien en su propio ecosistema, es decir analizar por ejemplo los comentarios de Twitter son bastante interesantes cuando se refieren a una marca; pero el reto que no se ha cumplido es enlazar este mundo con los clientes de cada organización.
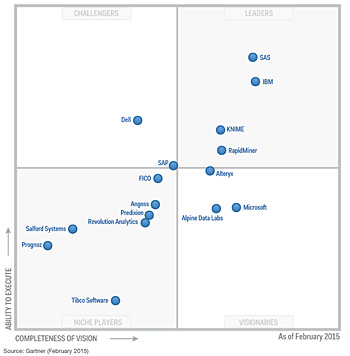
![KNIME[1]](http://www.peruanalitica.com/wp-content/uploads/2015/03/KNIME1.jpg)